Capítulo 3 Análisis Exploratorio de Datos (EDA)
En esta sección se exploran las variables ya transformadas para identificar patrones, distribuciones y relaciones relevantes para el objetivo predictivo.
3.1 Estadísticas descriptivas de variables numéricas
tabla_descriptiva <- df %>%
select(edad_anos, dias_recuperacion, dias_hasta_fallecimiento) %>%
pivot_longer(everything(), names_to = "Variable", values_to = "Valor") %>%
group_by(Variable) %>%
summarise(
N = sum(!is.na(Valor)),
Media = round(mean(Valor, na.rm = TRUE), 2),
"Desv. Est" = round(sd(Valor, na.rm = TRUE), 2),
Minimo = round(min(Valor, na.rm = TRUE), 2),
Q1 = round(quantile(Valor, 0.25, na.rm = TRUE), 2),
Mediana = round(median(Valor, na.rm = TRUE), 2),
Q3 = round(quantile(Valor, 0.75, na.rm = TRUE), 2),
Maximo = round(max(Valor, na.rm = TRUE), 2)
)
tabla_descriptiva %>%
kable(caption = "Estadísticas descriptivas de variables numéricas") %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "responsive"),
full_width = TRUE,
position = "center"
) %>%
row_spec(0, bold = TRUE)| Variable | N | Media | Desv. Est | Minimo | Q1 | Mediana | Q3 | Maximo |
|---|---|---|---|---|---|---|---|---|
| dias_hasta_fallecimiento | 13130 | 42.41 | 74.91 | 0 | 11 | 19 | 31 | 543 |
| dias_recuperacion | 403408 | 23.23 | 28.58 | 2 | 14 | 15 | 21 | 386 |
| edad_anos | 419061 | 40.25 | 19.52 | 0 | 26 | 38 | 54 | 113 |
3.2 Distribución de la variable edad
ggplot(df %>% filter(!is.na(edad_anos)), aes(y = edad_anos)) +
geom_boxplot(
fill = "#2C3E50", color = "black", width = 0.4,
outlier.color = "#E74C3C", outlier.size = 2
) +
labs(
title = "Distribución de edad en casos positivos de COVID-19 — Atlántico",
y = "Edad en años", x = NULL
) +
theme_classic(base_size = 15) +
theme(plot.title = element_text(face = "bold", hjust = 0.5),
axis.text = element_text(color = "black"))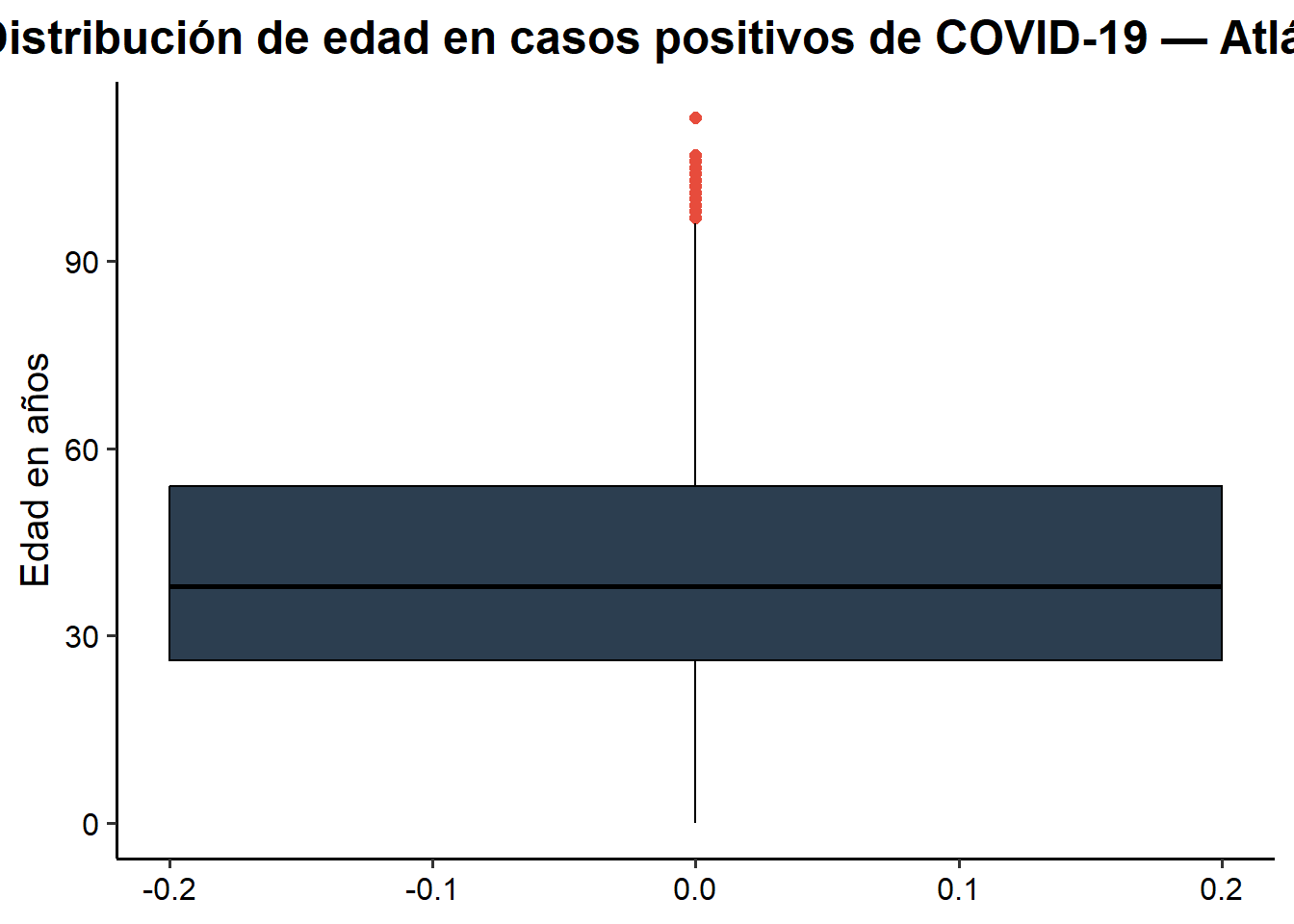
Figure 3.1: Boxplot de la distribución de edad en casos positivos de COVID-19 — Atlántico
ggplot(df %>% filter(!is.na(edad_anos)), aes(x = edad_anos)) +
geom_histogram(binwidth = 10, boundary = 0, color = "white", fill = "steelblue") +
geom_text(stat = "bin", binwidth = 10,
aes(label = after_stat(count)), vjust = -0.5, size = 3) +
scale_y_continuous(labels = comma) +
labs(
title = "Histograma de edad de casos positivos de COVID-19 — Atlántico",
x = "Edad en años", y = "Frecuencia"
) +
theme_minimal(base_size = 14)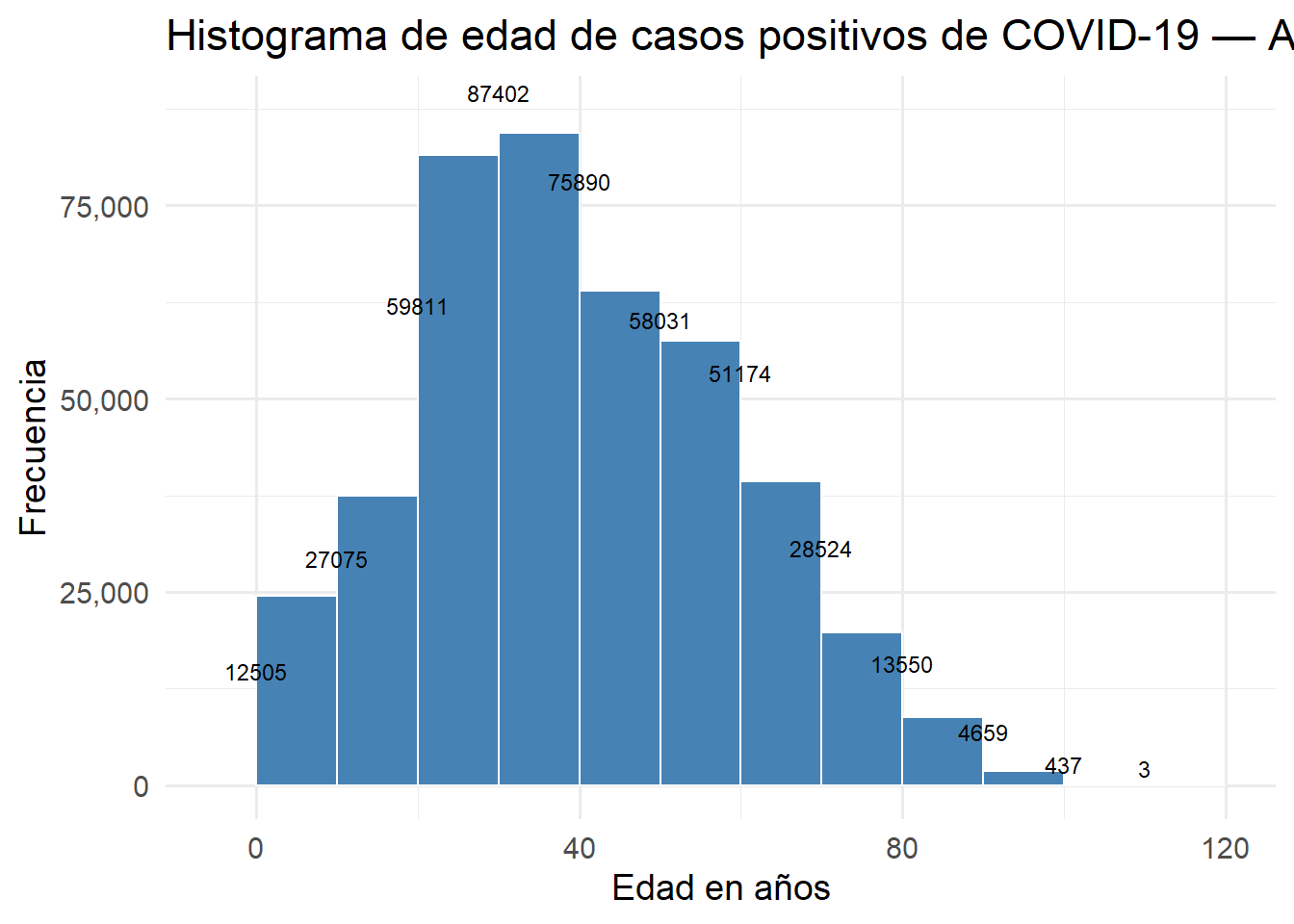
Figure 3.2: Histograma de edad de casos positivos de COVID-19 — Atlántico
La mayor proporción de casos positivos corresponde a personas entre 30 y 40 años, lo que refleja que la población económicamente activa fue la más expuesta al contagio, probablemente por mayor movilidad y contacto social durante la pandemia.
3.3 Evolución temporal de casos
df <- df %>%
mutate(
fecha_notif_date = as.Date(
format(as.POSIXct(fecha_de_notificacion, tryFormats = c(
"%Y-%m-%d %H:%M:%S", "%Y-%m-%d", "%d/%m/%Y", "%d-%m-%Y"
), tz = "UTC"), "%Y-%m-%d")
)
)
df_temporal <- df %>%
filter(!is.na(fecha_notif_date)) %>%
mutate(
ano = as.integer(format(fecha_notif_date, "%Y")),
mes = as.integer(format(fecha_notif_date, "%m"))
) %>%
filter(ano >= 2020, ano <= 2024)
anos_reales <- sort(unique(df_temporal$ano))
tabla_casos <- df_temporal %>%
count(ano, mes) %>%
complete(ano = anos_reales, mes = 1:12, fill = list(n = 0)) %>%
pivot_wider(names_from = mes, values_from = n, values_fill = 0) %>%
arrange(ano) %>%
mutate(ano = as.character(ano))
for (m in as.character(1:12)) {
if (!m %in% colnames(tabla_casos)) tabla_casos[[m]] <- 0
}
tabla_casos <- tabla_casos %>% select(ano, as.character(1:12))
colnames(tabla_casos) <- c("Año","Ene","Feb","Mar","Abr","May","Jun",
"Jul","Ago","Sep","Oct","Nov","Dic")
tabla_casos %>%
kable(caption = "Casos positivos de COVID-19 por mes y año en el Atlántico",
align = c("l", rep("r", 12)),
format.args = list(big.mark = ".")) %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "responsive"),
full_width = TRUE, position = "center"
) %>%
row_spec(0, bold = TRUE) %>%
column_spec(1, bold = TRUE)## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso| Año | Ene | Feb | Mar | Abr | May | Jun | Jul | Ago | Sep | Oct | Nov | Dic |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020 | 0 | 0 | 71 | 575 | 6.715 | 26.486 | 24.270 | 7.155 | 3.445 | 5.045 | 7.562 | 18.555 |
| 2021 | 19.279 | 7.477 | 53.350 | 71.715 | 27.589 | 17.837 | 13.620 | 5.363 | 7.261 | 8.849 | 8.080 | 8.839 |
| 2022 | 49.631 | 3.209 | 316 | 318 | 2.115 | 8.740 | 2.009 | 341 | 120 | 406 | 1.136 | 214 |
| 2023 | 186 | 156 | 101 | 144 | 353 | 173 | 64 | 29 | 19 | 22 | 22 | 49 |
| 2024 | 50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Se observa un pico de casos en el primer semestre de 2021. En 2023 los casos se redujeron considerablemente, coincidiendo con la masificación de la vacunación en el departamento.
3.4 Casos por municipio — Mapa interactivo
coords_municipios <- tibble(
nombre_municipio = c(
"BARRANQUILLA","SOLEDAD","MALAMBO","SABANALARGA","GALAPA",
"BARANOA","SANTO TOMAS","PALMAR DE VARELA","REPELON","MANATÍ",
"CAMPO DE LA CRUZ","CANDELARIA","PONEDERA","JUAN DE ACOSTA",
"TUBARA","USIACURI","LURUACO","SUAN","SANTA LUCIA","PIOJO",
"POLO NUEVO","SABANAGRANDE","PUERTO COLOMBIA"
),
lat = c(
10.9639, 10.9174, 10.8451, 10.6264, 10.9044,
10.8044, 10.7514, 10.7253, 10.5103, 10.4411,
10.3803, 10.4633, 10.6397, 10.8044, 10.9194,
10.7394, 10.6097, 10.2900, 10.3292, 10.7917,
10.5611, 10.7944, 11.0253
),
lon = c(
-74.7964, -74.7694, -74.7856, -74.9181, -74.8764,
-74.9786, -74.7556, -74.7539, -75.0706, -74.9706,
-74.8833, -74.8836, -74.9222, -75.0833, -74.9444,
-74.9889, -75.0931, -74.7278, -74.7703, -75.1028,
-75.0194, -74.7556, -74.9642
)
)
casos_mun <- df %>%
mutate(nombre_municipio = str_to_upper(str_trim(nombre_municipio))) %>%
count(nombre_municipio, name = "casos") %>%
arrange(desc(casos))
mapa_df <- coords_municipios %>%
left_join(casos_mun, by = "nombre_municipio") %>%
filter(!is.na(casos))
pal <- colorNumeric(palette = "YlOrRd", domain = mapa_df$casos)
leaflet(mapa_df) %>%
addProviderTiles(providers$CartoDB.Positron) %>%
addCircleMarkers(
lng = ~lon, lat = ~lat,
radius = ~scales::rescale(casos, to = c(5, 30)),
color = ~pal(casos),
fillColor = ~pal(casos),
fillOpacity = 0.8,
stroke = TRUE,
weight = 1,
popup = ~paste0(
"<b>", nombre_municipio, "</b><br>",
"Casos: <b>", format(casos, big.mark = "."), "</b>"
),
label = ~paste0(nombre_municipio, ": ", format(casos, big.mark = "."))
) %>%
addLegend(
position = "bottomright",
pal = pal,
values = ~casos,
title = "Casos COVID-19",
labFormat = labelFormat(big.mark = ".")
) %>%
setView(lng = -74.9, lat = 10.7, zoom = 9)## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confuso
## Warning in prettyNum(.Internal(format(x, trim, digits, nsmall, width, 3L, :
## 'big.mark' y 'decimal.mark' son ambos '.', lo cual puede ser confusoFigure 3.3: Distribución geográfica de casos COVID-19 por municipio en el Atlántico
El mapa muestra la distribución geográfica de casos en el Atlántico. Barranquilla concentra el mayor número de casos (círculo más grande y color más intenso), seguida por Soledad y Malambo. Los municipios del sur del departamento presentaron menor cantidad de casos en términos absolutos.
3.5 Casos por municipio — Gráfico de barras
top_mun <- df %>%
mutate(nombre_municipio = str_to_upper(str_trim(nombre_municipio))) %>%
count(nombre_municipio) %>%
arrange(desc(n)) %>%
slice(1:12)
ggplot(top_mun, aes(x = reorder(nombre_municipio, n), y = n)) +
geom_col(fill = "steelblue") +
geom_text(aes(label = comma(n)), hjust = -0.1, size = 3.5) +
coord_flip() +
scale_y_continuous(labels = comma, expand = expansion(mult = c(0, 0.18))) +
theme_minimal(base_size = 13) +
labs(
title = "Top 12 municipios con más casos positivos de COVID-19",
x = "Municipio", y = "Número de casos"
)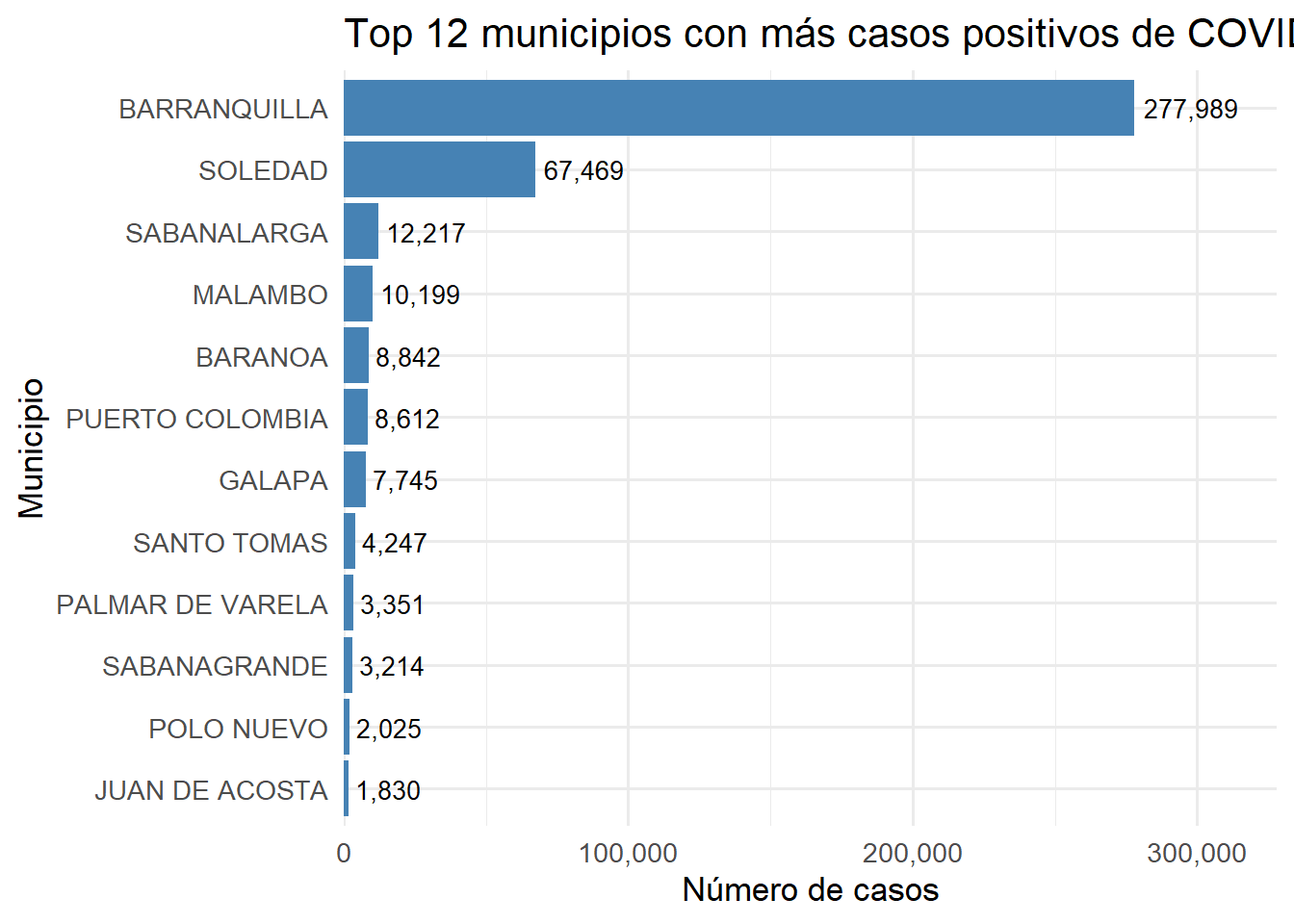
Figure 3.4: Top 12 municipios con más casos positivos de COVID-19
Barranquilla concentra la gran mayoría de casos positivos, seguida por Soledad y Sabanalarga. Este patrón es esperado dado que Barranquilla es el municipio más poblado del departamento y su principal centro económico.
3.6 Tasa de mortalidad por municipio
tabla_mort <- df %>%
mutate(nombre_municipio = str_to_upper(str_trim(nombre_municipio))) %>%
filter(
!is.na(nombre_municipio),
!is.na(recuperado),
recuperado %in% c("Recuperado", "Fallecido")
) %>%
count(nombre_municipio, recuperado) %>%
group_by(nombre_municipio) %>%
mutate(porcentaje = n / sum(n) * 100) %>%
ungroup()
orden_municipios <- tabla_mort %>%
filter(recuperado == "Fallecido") %>%
arrange(desc(porcentaje)) %>%
pull(nombre_municipio)
tabla_mort <- tabla_mort %>%
mutate(nombre_municipio = factor(nombre_municipio, levels = orden_municipios))
ggplot(tabla_mort, aes(x = porcentaje, y = nombre_municipio, fill = recuperado)) +
geom_col() +
geom_text(
aes(label = sprintf("%.1f%%", porcentaje)),
position = position_stack(vjust = 0.5),
size = 3.2, color = "white", fontface = "bold"
) +
scale_fill_manual(values = c("Recuperado" = "#1ABC9C", "Fallecido" = "#E74C3C")) +
scale_x_continuous(limits = c(0, 100), labels = function(x) paste0(x, "%")) +
labs(
title = "Distribución porcentual de casos por municipio",
x = "Porcentaje (%)", y = "Municipio", fill = NULL
) +
theme_minimal(base_size = 12) +
theme(legend.position = "top")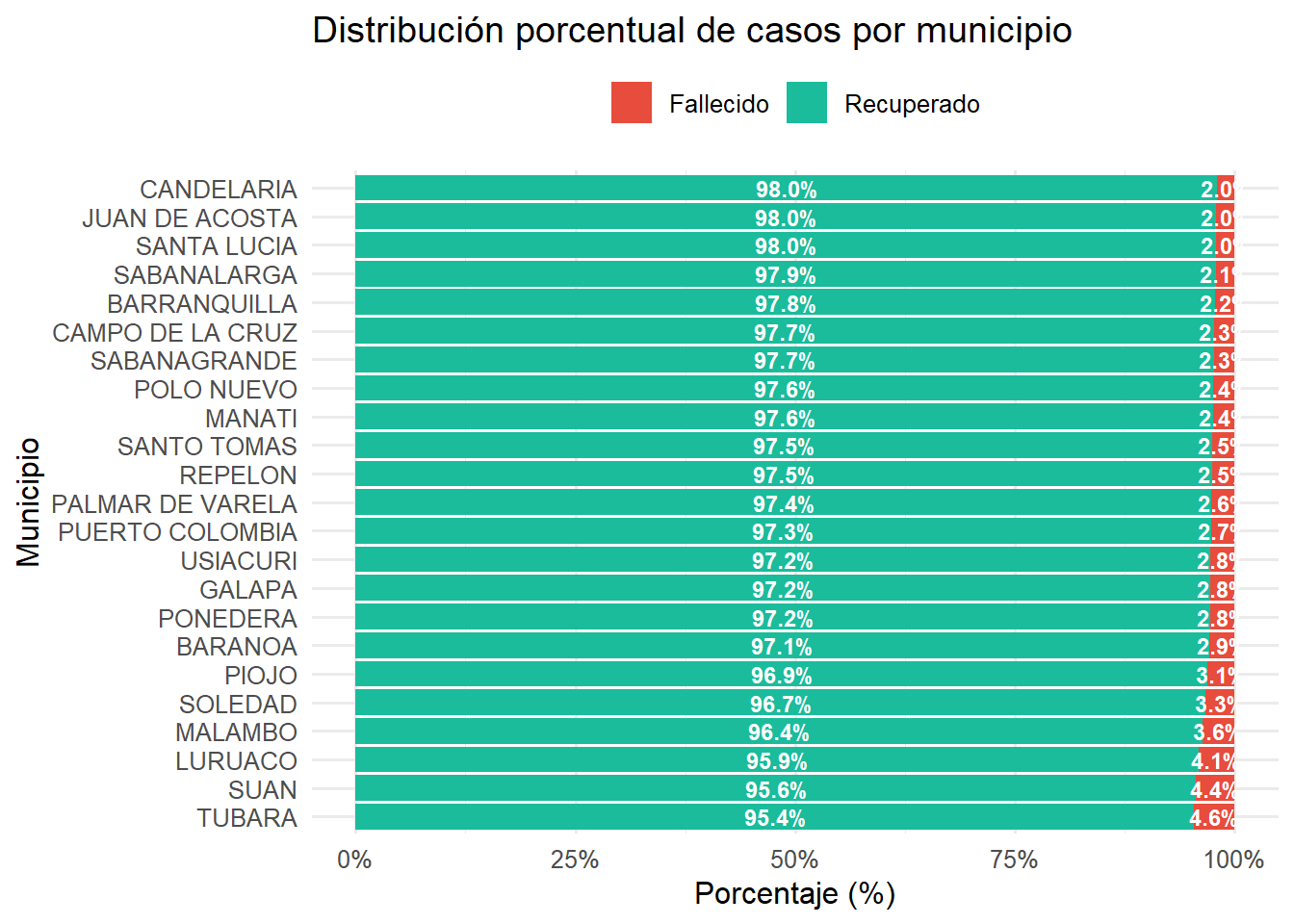
Figure 3.5: Distribución porcentual de recuperados vs fallecidos por municipio
Tubará fue el municipio con mayor tasa de mortalidad (aproximadamente 5%), mientras que Candelaria, Juan de Acosta y Santa Lucía registraron las mejores tasas de recuperación (cercanas al 98%).
3.7 Tipo de contagio
contagio_tabla <- df %>%
filter(!is.na(tipo_de_contagio)) %>%
count(tipo_de_contagio) %>%
mutate(porcentaje = n / sum(n))
ggplot(contagio_tabla,
aes(x = reorder(tipo_de_contagio, -porcentaje),
y = porcentaje, fill = tipo_de_contagio)) +
geom_col(show.legend = FALSE) +
geom_text(
aes(label = percent(porcentaje, accuracy = 0.1)),
vjust = -0.5, size = 4, fontface = "bold"
) +
scale_y_continuous(labels = percent, expand = expansion(mult = c(0, 0.1))) +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Distribución de tipos de contagio en COVID-19 — Atlántico",
x = "Tipo de contagio", y = "Porcentaje"
) +
theme_minimal(base_size = 14)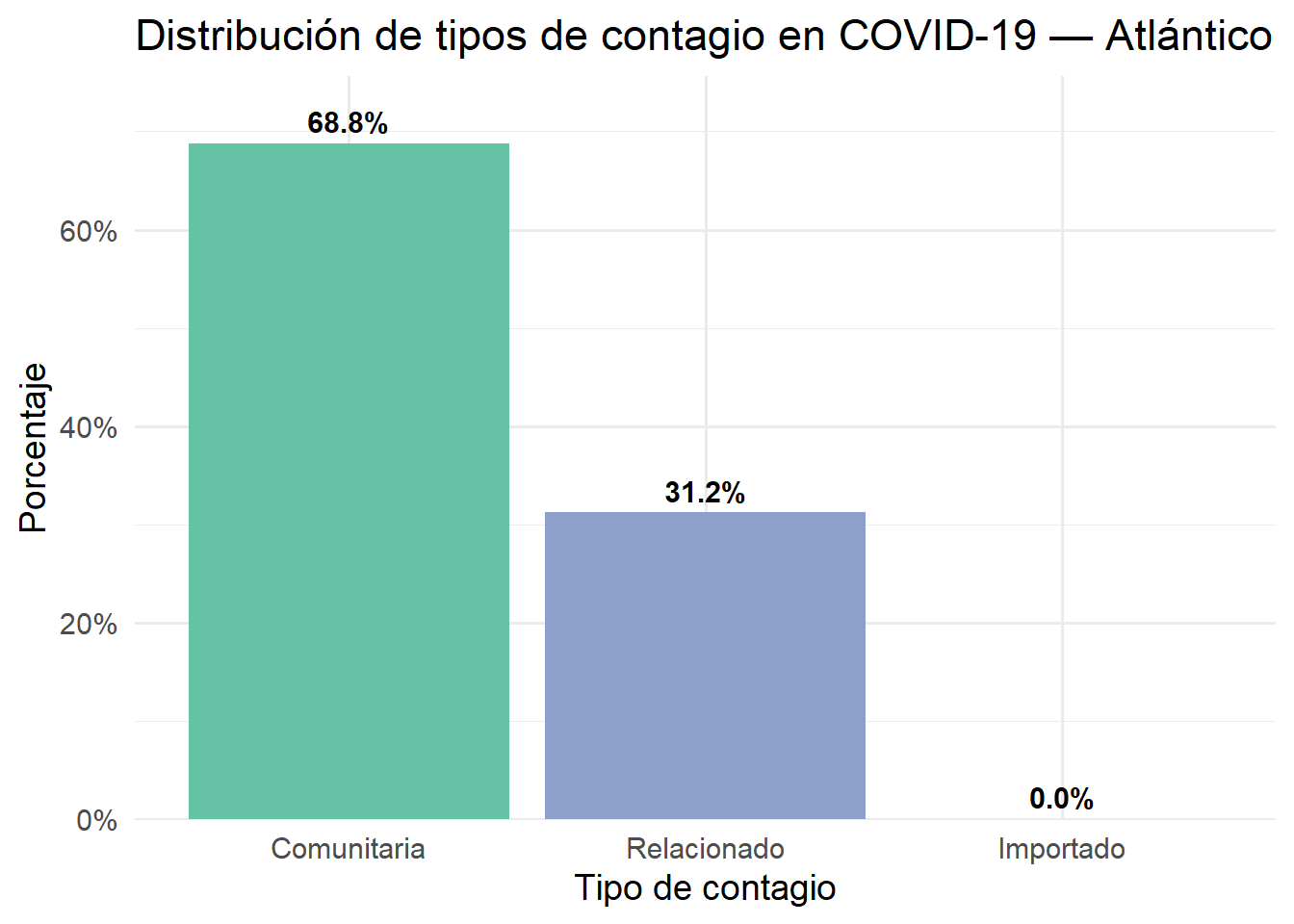
Figure 3.6: Distribución de tipos de contagio en COVID-19 — Atlántico
El tipo de contagio más frecuente es el comunitario (68%), es decir, cuando no se identifica la fuente exacta del contagio. El contagio relacionado (contacto directo con un caso confirmado) representa el 31%, y el importado es el menos común con menos del 1%.
3.8 Distribución por sexo
sexo_tabla <- df %>%
filter(!is.na(sexo), sexo %in% c("M", "F")) %>%
count(sexo) %>%
mutate(porcentaje = n / sum(n))
ggplot(sexo_tabla, aes(x = sexo, y = n, fill = sexo)) +
geom_col(show.legend = FALSE) +
geom_text(
aes(label = paste0(comma(n), "\n(", percent(porcentaje, accuracy = 0.1), ")")),
vjust = -0.3, size = 4, fontface = "bold"
) +
scale_y_continuous(labels = comma, expand = expansion(mult = c(0, 0.18))) +
scale_fill_manual(values = c("M" = "#3498DB", "F" = "#E91E8C")) +
labs(
title = "Distribución de casos positivos de COVID-19 según sexo",
x = "Sexo", y = "Número de casos"
) +
theme_minimal(base_size = 14)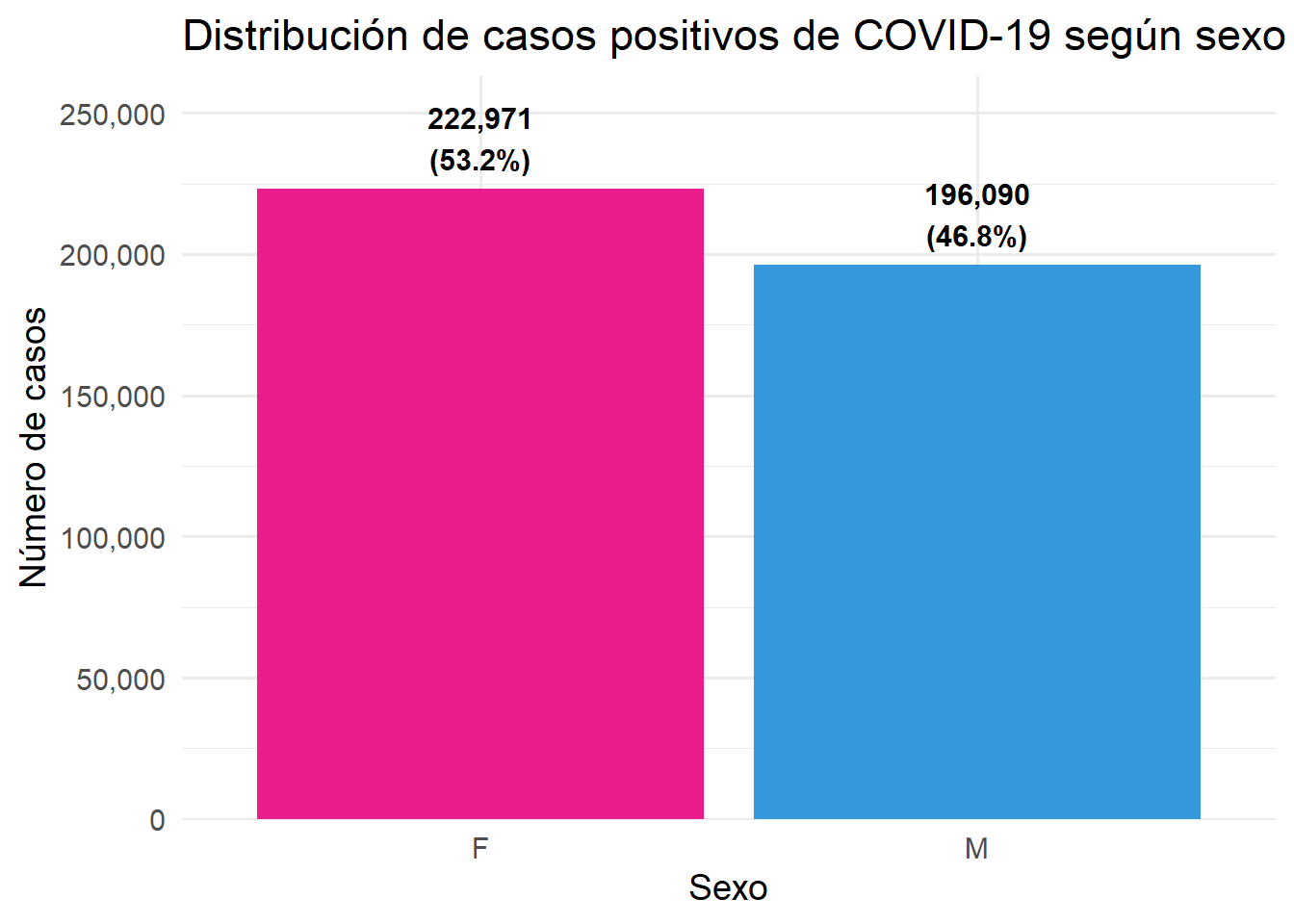
Figure 3.7: Distribución de casos positivos de COVID-19 según sexo
Se observa una mayor proporción de casos positivos en el género masculino. Esto puede estar relacionado con mayor exposición laboral y menor adherencia a medidas de bioseguridad en algunos contextos.
3.9 Distribución de recuperados vs fallecidos
caso_recuperado <- df %>%
filter(recuperado %in% c("Recuperado", "Fallecido")) %>%
count(recuperado) %>%
mutate(porcentaje = n / sum(n))
ggplot(caso_recuperado, aes(x = recuperado, y = n, fill = recuperado)) +
geom_col(show.legend = FALSE) +
geom_text(
aes(label = paste0(comma(n), "\n(", percent(porcentaje, accuracy = 0.1), ")")),
vjust = -0.3, size = 4.5, fontface = "bold"
) +
scale_y_continuous(labels = comma, expand = expansion(mult = c(0, 0.18))) +
scale_fill_manual(values = c("Recuperado" = "#1ABC9C", "Fallecido" = "#E74C3C")) +
labs(
title = "Casos recuperados y fallecidos de COVID-19 en el Atlántico",
x = NULL, y = "Número de casos"
) +
theme_minimal(base_size = 14)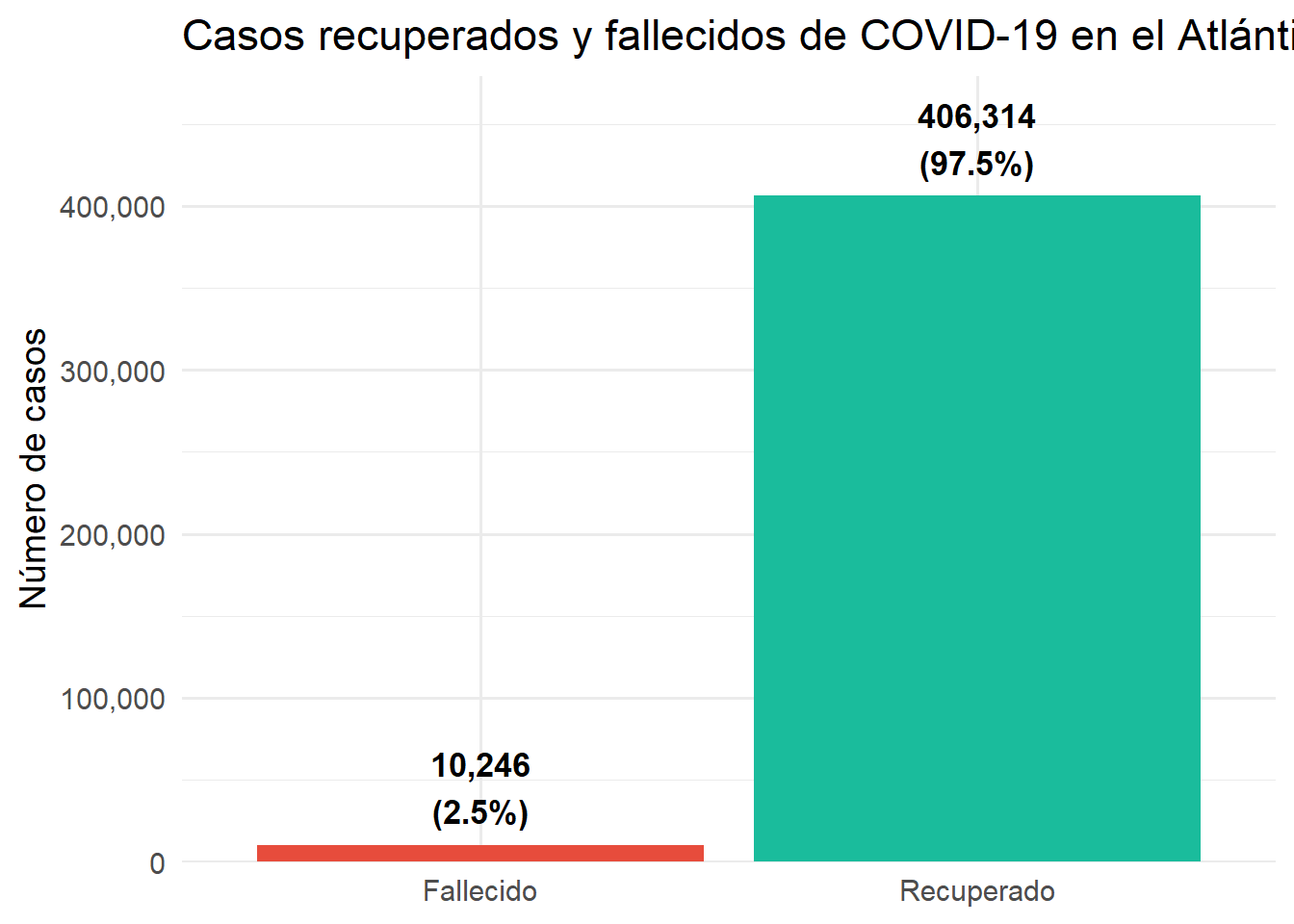
Figure 3.8: Casos recuperados y fallecidos de COVID-19 en el Atlántico
La tasa de mortalidad en el Atlántico fue del 2.5%, mientras que el 97.5% de los casos positivos se recuperaron. Aunque la tasa es relativamente baja, en términos absolutos representa una cantidad significativa de fallecimientos con impacto directo en las familias y el sistema de salud del departamento.
3.10 Distribución de días de recuperación
df_rec <- df %>% filter(!is.na(dias_recuperacion),
dias_recuperacion >= 0, dias_recuperacion <= 400)
med_rec <- median(df_rec$dias_recuperacion, na.rm = TRUE)
mean_rec <- mean(df_rec$dias_recuperacion, na.rm = TRUE)
ggplot(df_rec, aes(x = dias_recuperacion)) +
geom_histogram(bins = 50, fill = "lightgreen", color = "white") +
geom_vline(xintercept = med_rec, color = "#E74C3C", linewidth = 1,
linetype = "solid") +
geom_vline(xintercept = mean_rec, color = "#3498DB", linewidth = 1,
linetype = "dashed") +
annotate("text", x = med_rec + 8, y = Inf, vjust = 2,
label = paste0("Mediana: ", round(med_rec, 0)), color = "#E74C3C", size = 3.5) +
annotate("text", x = mean_rec + 8, y = Inf, vjust = 4,
label = paste0("Media: ", round(mean_rec, 0)), color = "#3498DB", size = 3.5) +
scale_y_continuous(labels = comma) +
labs(
title = "Histograma de días de recuperación",
x = "Días de recuperación", y = "Frecuencia"
) +
theme_minimal(base_size = 14)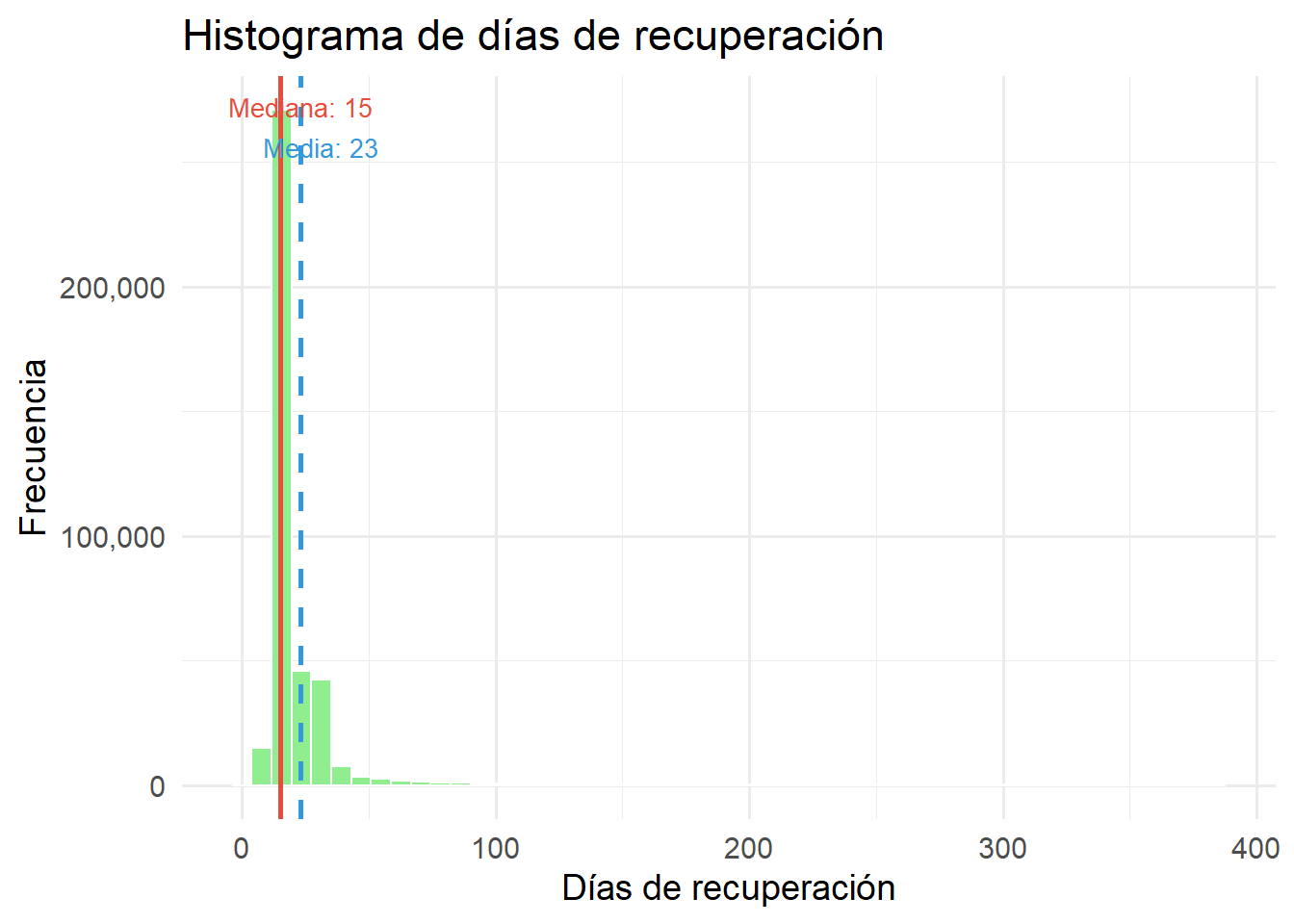
Figure 3.9: Histograma de días de recuperación
stats_rec <- df$dias_recuperacion
data.frame(
Estadístico = c("Número de casos","Media","Desviación estándar",
"Mínimo","Percentil 25 (Q1)","Mediana (Q2)",
"Percentil 75 (Q3)","Máximo"),
Valor = c(
sum(!is.na(stats_rec)),
round(mean(stats_rec, na.rm = TRUE), 2),
round(sd(stats_rec, na.rm = TRUE), 2),
round(min(stats_rec, na.rm = TRUE), 0),
round(quantile(stats_rec, 0.25, na.rm = TRUE), 0),
round(median(stats_rec, na.rm = TRUE), 0),
round(quantile(stats_rec, 0.75, na.rm = TRUE), 0),
round(max(stats_rec, na.rm = TRUE), 0)
)
) %>%
kable(caption = "Estadísticos descriptivos: Días de recuperación") %>%
kable_styling(
bootstrap_options = c("striped", "hover"),
full_width = FALSE, position = "center"
) %>%
row_spec(0, bold = TRUE)| Estadístico | Valor |
|---|---|
| Número de casos | 403408.00 |
| Media | 23.23 |
| Desviación estándar | 28.58 |
| Mínimo | 2.00 |
| Percentil 25 (Q1) | 14.00 |
| Mediana (Q2) | 15.00 |
| Percentil 75 (Q3) | 21.00 |
| Máximo | 386.00 |
La distribución presenta una fuerte asimetría positiva. El 50% de los pacientes se recuperaron entre 14 y 21 días. La media (23 días) supera a la mediana (15 días) por la influencia de casos extremos de hasta 386 días. La mediana es la mejor medida de tendencia central en esta distribución asimétrica.
3.11 Distribución de días hasta fallecimiento
df_fall <- df %>% filter(!is.na(dias_hasta_fallecimiento),
dias_hasta_fallecimiento >= 0)
med_fall <- median(df_fall$dias_hasta_fallecimiento, na.rm = TRUE)
mean_fall <- mean(df_fall$dias_hasta_fallecimiento, na.rm = TRUE)
ggplot(df_fall, aes(x = dias_hasta_fallecimiento)) +
geom_histogram(bins = 50, fill = "steelblue", color = "white") +
geom_vline(xintercept = med_fall, color = "#E74C3C", linewidth = 1,
linetype = "solid") +
geom_vline(xintercept = mean_fall, color = "#F39C12", linewidth = 1,
linetype = "dashed") +
annotate("text", x = med_fall + 8, y = Inf, vjust = 2,
label = paste0("Mediana: ", round(med_fall, 0)), color = "#E74C3C", size = 3.5) +
annotate("text", x = mean_fall + 8, y = Inf, vjust = 4,
label = paste0("Media: ", round(mean_fall, 0)), color = "#F39C12", size = 3.5) +
scale_y_continuous(labels = comma) +
labs(
title = "Días hasta fallecimiento en pacientes con COVID-19",
x = "Días hasta fallecer", y = "Frecuencia"
) +
theme_minimal(base_size = 14)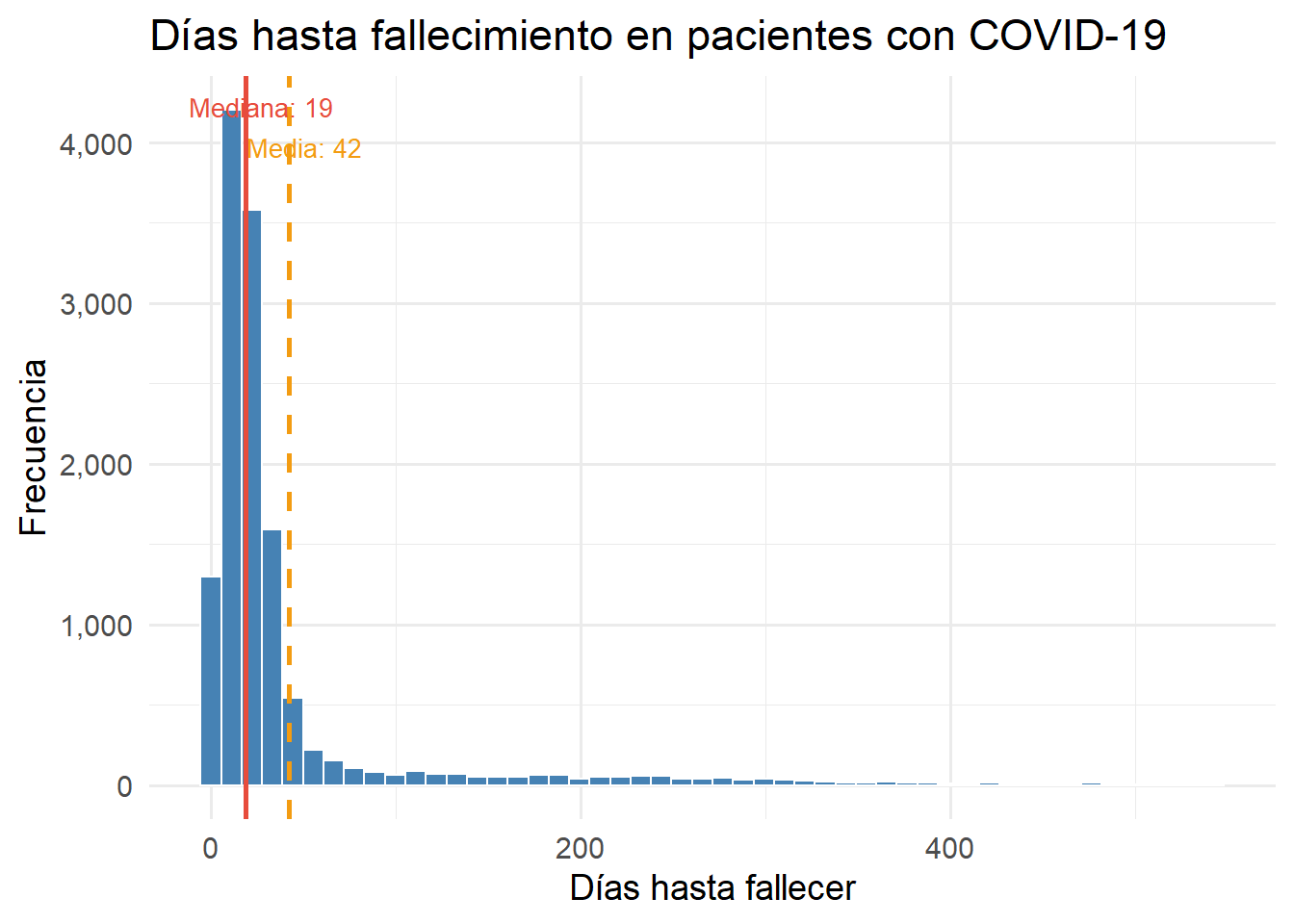
Figure 3.10: Días hasta fallecimiento en pacientes con COVID-19
stats_fall <- df$dias_hasta_fallecimiento
data.frame(
Estadístico = c("Número de casos","Media","Desviación estándar",
"Mínimo","Percentil 25 (Q1)","Mediana (Q2)",
"Percentil 75 (Q3)","Máximo"),
Valor = c(
sum(!is.na(stats_fall)),
round(mean(stats_fall, na.rm = TRUE), 2),
round(sd(stats_fall, na.rm = TRUE), 2),
round(min(stats_fall, na.rm = TRUE), 0),
round(quantile(stats_fall, 0.25, na.rm = TRUE), 0),
round(median(stats_fall, na.rm = TRUE), 0),
round(quantile(stats_fall, 0.75, na.rm = TRUE), 0),
round(max(stats_fall, na.rm = TRUE), 0)
)
) %>%
kable(caption = "Estadísticos descriptivos: Días hasta fallecimiento") %>%
kable_styling(
bootstrap_options = c("striped", "hover"),
full_width = FALSE, position = "center"
) %>%
row_spec(0, bold = TRUE)| Estadístico | Valor |
|---|---|
| Número de casos | 13130.00 |
| Media | 42.41 |
| Desviación estándar | 74.91 |
| Mínimo | 0.00 |
| Percentil 25 (Q1) | 11.00 |
| Mediana (Q2) | 19.00 |
| Percentil 75 (Q3) | 31.00 |
| Máximo | 543.00 |
Al igual que los días de recuperación, la distribución presenta fuerte asimetría positiva con casos extremos de hasta 543 días. La mediana de 19 días es la medida más representativa del comportamiento típico de esta variable.
3.12 Correlación entre variables numéricas
datos_corr <- df %>%
select(edad_anos, dias_recuperacion, dias_hasta_fallecimiento) %>%
na.omit()
matriz_corr <- cor(datos_corr, method = "spearman")
matriz_larga <- as.data.frame(as.table(matriz_corr))
colnames(matriz_larga) <- c("Variable1", "Variable2", "Correlacion")
ggplot(matriz_larga, aes(x = Variable1, y = Variable2, fill = Correlacion)) +
geom_tile(color = "white") +
geom_text(aes(label = round(Correlacion, 2)), color = "black", size = 5) +
scale_fill_gradient2(low = "blue", mid = "white", high = "red",
midpoint = 0, limits = c(-1, 1)) +
labs(
title = "Mapa de calor de correlaciones (Spearman)",
x = "", y = "", fill = "Correlación"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 15, hjust = 1))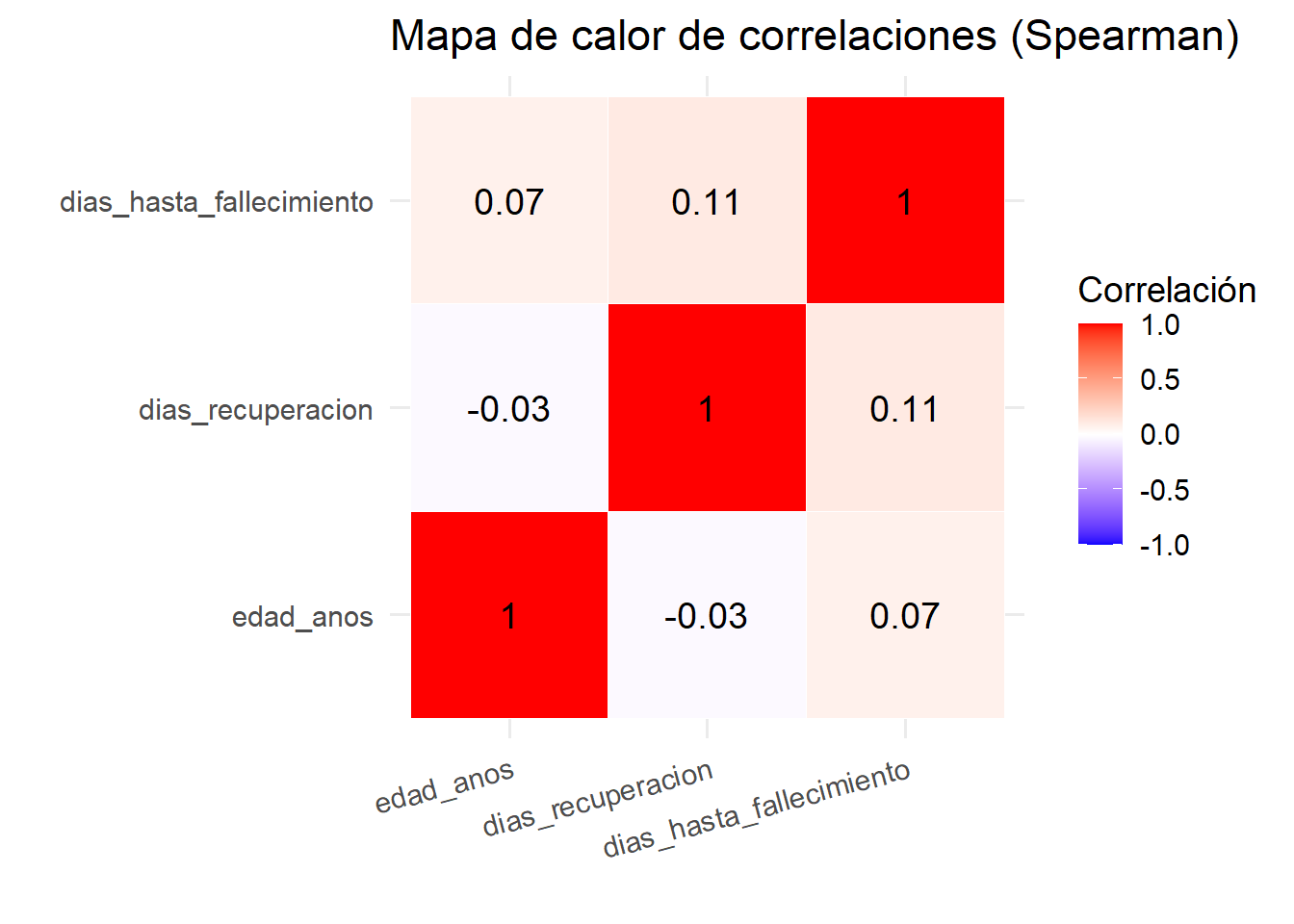
Figure 3.11: Mapa de calor de correlaciones de Spearman
La matriz de correlación de Spearman muestra que no existe correlación significativa entre la edad, los días de recuperación y los días hasta fallecimiento. Esto indica que la edad por sí sola no determina el tiempo de recuperación, lo que sugiere que otros factores (comorbilidades, tipo de contagio, acceso a salud) podrían ser más determinantes. Este hallazgo es relevante para la selección de variables en el modelo predictivo.